

The market for agentic AI security tools is growing fast — and so are the marketing claims. “Agentic AI Offensive Security” has become a phrase attached to everything from glorified scanners to genuinely novel platforms capable of chaining exploits the way a skilled human attacker would.
To cut through the noise, we ran a head-to-head benchmark: RidgeGen (our own platform), Shannon, and Strix — three systems that all claim to represent the state of the art in agentic AI-based penetration testing — against a single, well-understood target: the OWASP Juice Shop. The Juice Shop is a deliberately vulnerable Node.js application designed as a benchmark for security tools, containing 110 structured CTF-style challenges spanning SQL injection, broken access control, business logic flaws, and more.
All three systems were run sequentially under the same conditions. Each platform received only the target URL of a freshly deployed OWASP Juice Shop instance, recreated from the same Docker image for each run in an isolated cloud environment. The LLM backend was held constant across all three platforms, using Gemini 3 Flash throughout, so the variable under test was the system itself: how it reasons, plans, executes, and validates findings. We did not give any platform explicit instructions to maximize CTF score, instead, we use Juice Shop’s internal challenge counter as a proxy for successful exploitation progress. That number is generated by the target itself, not by our harness, so it serves as a useful approximation of how much meaningful exploitation a system achieved during the run. In parallel, we collected all findings produced during execution, compiled a final report for each platform, and manually verified the reported issues.
Because Juice Shop is a public benchmark, we also applied a three-layer anticheat methodology. First, each run was isolated so the agent could communicate only with the target application and the LLM provider, preventing web searches or retrieval of public solution material. Second, we parsed model messages and execution traces for known cheating patterns, including benchmark-specific behaviors that can trigger challenge completion without actually demonstrating the underlying exploit. Third, we reviewed the traces with an LLM-as-judge step to assess whether a challenge appeared to be solved through a clean reasoning and exploitation path against the live target, or whether the trajectory relied on memorized internal Juice Shop knowledge or scoring shortcuts. Together, these controls were designed to ensure the benchmark measured real exploitation behavior rather than benchmark gaming.
The Metrics at a Glance
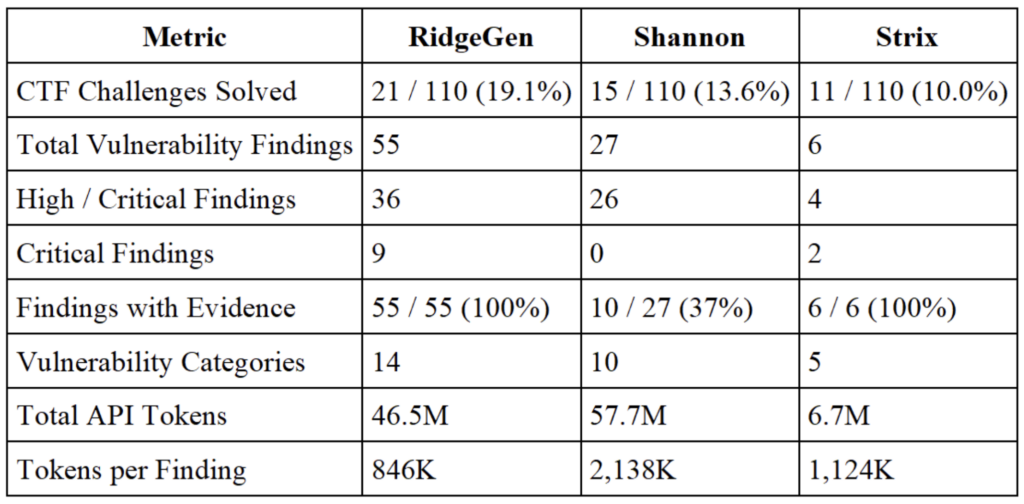
Metric 1: The Findings Depth
Raw challenge counts are a useful headline number, but the more revealing metric is what each system actually found — and whether those findings hold up under scrutiny. This is where the differences between the platforms become stark.
RidgeGen produced 55 vulnerability findings. Every single one is backed by concrete execution evidence — full HTTP requests, server responses, extracted data, and reproducible reproduction steps. There is no theoretical hedging, no template-driven speculation: every finding is a demonstrated exploit.
Shannon reported 27 findings. 10 of those 27 (37%) include actual exploitation evidence. The remaining 17 describe potential vulnerabilities without demonstrating that they were actually exploited against the target. Findings like INJ-SSTI-01 (Server-Side Template Injection), INJ-DESER-01 (Insecure Deserialization), and multiple XSS/access control entries appear to be vulnerability-class templates rather than confirmed exploits.
Strix achieved 6 evidence-backed findings total and completed its run in 862 seconds. Its 100% evidence rate reflects genuine verification discipline — but 6 findings in an environment with 110 challenges leaves most of the attack surface uncovered.
At 63% unconfirmed findings, Shannon’s output requires significant manual validation before any of its unique findings can be trusted. RidgeGen’s 0% hallucination rate means every finding goes directly into the report with full confidence.
Metric 2: The Unique Findings
Another dimension for comparing the three tools is the distribution of findings from each system. Of the 75 total unique findings across all three platforms, 38 (54%) were exclusive to RidgeGen—neither Shannon nor Strix reported them.. Of the 75 total unique findings across all
three platforms, 38 (54%) were exclusive to RidgeGen. Neither Shannon nor Strix reported them.
Example 1: The JWT Attack Chain
The clearest illustration of RidgeGen’s approach is how it handled the JWT alg:none vulnerability. Most tools that find this vulnerability report it as a single finding and move on. RidgeGen found the initial bypass — then spent the remainder of its scan systematically testing the forged JWT against every authenticated API endpoint in the application.
The result was a cascade of findings that neither Shannon nor Strix discovered:
· Critical JWT alg:none bypass enabling identity forgery
· Critical Role manipulation via forged JWT (vertical privilege escalation)
· Critical /api/Users/:id — full account takeover via mass assignment
· Critical /api/Products/:id — unauthenticated price and description manipulation
· High 12+ distinct IDOR findings across basket, address, complaint, recycle, and privacy endpoints
· High Admin-level enumeration and deletion across feedback, complaints, and user records
This “exploit one, test everywhere” methodology is what separates genuine penetration testing from pattern-based scanning. It requires the system to understand application topology, maintain belief state across a long session, and reason about which endpoints are likely to share the same access control flaw.
Example 2: Business Logic
RidgeGen was the only system to discover any business logic vulnerabilities — a class of flaws that pattern-matching tools structurally cannot find because they require semantic understanding of how the application is supposed to behave.
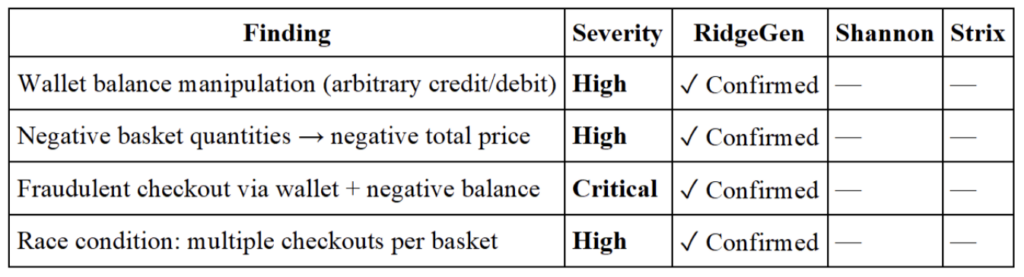
To find these vulnerabilities, a system needs to understand that wallets and baskets interact at checkout, that negative quantities are not prevented at the item level, and that a race condition is exploitable when basket state isn’t properly locked before order finalization. These are reasoning tasks, not search tasks.
Metric 3: Severity of Findings
RidgeGen was the only system to identify Critical-severity vulnerabilities. Its 9 Critical findings include SQL injection enabling full authentication bypass, JWT forgery enabling identity impersonation across the entire application, mass assignment vulnerabilities enabling complete account takeover, and a business logic chain that enables fraudulent financial transactions. Shannon and Strix found zero Critical-severity issues.
Metric 4: Cost & Efficiency
Shannon’s 57.7M total run tokens — for 27 findings, most without evidence — represents an burn rate at 2138K tokens per finding. Strix used the fewest tokens but produced very few findings, resulting in a high token-per-finding ratio and cost efficiency that ranks second after RidgeGen.
RidgeGen delivered the best result across every efficiency dimension, 846K tokens per confirmed finding — while completing the testing and producing 55 zero-hallucination findings. When findings require no manual evidence review before acting on them, the true efficiency advantage compounds further.
Why Do We See Different Results? – The Architecture Behind Them
The results point to meaningful architectural design differences between the tools.
Beliefs memory drives depth. RidgeGen’s structured Commander/Specialist/Reflector architecture maintains an explicit model of what it has tested and what it has learned in terms of beliefs (i.e. findings that have been verified). When it discovered the JWT alg:none bypass, that knowledge propagated into its planning state and redirected subsequent test execution toward endpoints likely to be affected. Systems without persistent belief state tend to treat each tool call as independent, missing the compounding value of chained exploitation.
Evidence validation must be architectural, not optional. Compared with other systems, RidgeGen enforces evidence as an architectural invariant: no finding enters the report without concrete execution output.
Breadth of reasoning drives coverage. RidgeGen’s ability to chain exploits across the full application surface — discovering 55 findings across 14 categories — reflects the compounding advantage of maintaining belief state and systematically exploring adjacent attack surfaces from every discovered exploit.
Verdict
Across every dimension that matters for production use: challenge coverage, finding depth, evidence quality, vulnerability category breadth, and cost efficiency, RidgeGen leads this benchmark by a substantial margin. Its 21 solved challenges, 55 zero-hallucination findings, and 846K tokens-per-finding aren’t just better numbers: they reflect a fundamentally different approach to agentic penetration testing. The system reasons about applications rather than scanning them, chains exploits rather than cataloguing vulnerability classes, and validates findings through execution rather than inference.
Appendix
Findings Category Breakdown
Across 80 normalized vulnerability entries spanning 8 attack categories, the following matrix maps what each system found — and crucially, whether it was backed by execution evidence (E) or merely theoretical (T).
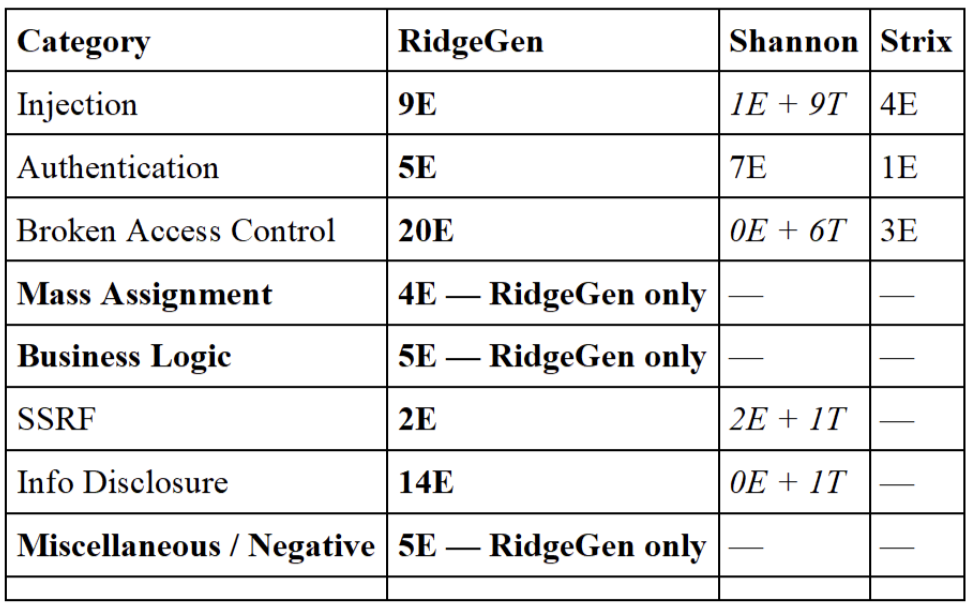
Categories D, E, and H (Mass Assignment, Business Logic, Miscellaneous/Negative) are exclusive to RidgeGen. Category C (Broken Access Control) shows the sharpest quality divide: 20 confirmed findings vs. 6 theoretical with zero exploitation evidence from Shannon.
Findings Overlap & Uniqueness
Of the 75 total unique findings across all three platforms, the distribution by overlap reveals just how concentrated discovery was in RidgeGen’s favor.
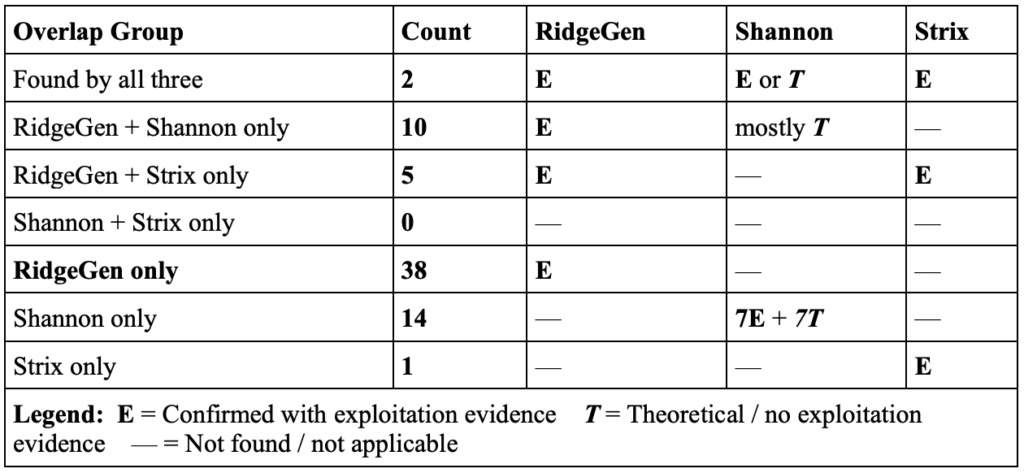
Key takeaway: 54% of all unique findings (38 of 70) were discovered exclusively by RidgeGen. Shannon and Strix share zero findings between themselves — every vulnerability found by more than one system was also found by RidgeGen.
Two numbers stand out. First: 54% of all unique findings (38 of 70) were discovered only by RidgeGen — spanning critical vulnerability classes like mass assignment, business logic, and IDOR chains that require multi-step reasoning. Second: Shannon and Strix share zero exclusive findings between them. Every vulnerability found by more than one system was also found by RidgeGen, which makes RidgeGen’s coverage the effective superset of the combined output.