

The security and compliance problem of disposable AI-generated code, and why validation must keep pace with autonomous generation.
With Contributions from Claudionor Coelho (former Chief AI Officer at Zscaler) and Lydia Zhang (CEO of Ridge Security).
Software used to be slow enough for governance to keep up, and enterprise controls were built around that cadence. AI coding agents have changed the speed of creation without changing the speed of review. The resulting gap is becoming a practical source of enterprise risk. This article examines one concrete instance of that gap — disposable AI-generated code — from boardroom risk down to the syscall, and argues that security validation has to operate on the same clock as the systems it protects.
1. The Problem: Disposable Code Bypasses the Control Pipeline
Many employees can now produce working software in minutes. Open a terminal, describe the goal to a coding agent such as Claude Code or OpenAI’s Codex, and within a few exchanges there may be a running application, a local environment, seeded data, and a URL to click. The old barrier between “people who can build software” and “everyone else” is much lower. A product manager can stand up an internal dashboard over lunch. A finance analyst can wire a model to a live data feed before a meeting. Neither person needs to understand sockets, certificates, or dependency resolution to get something that appears to work.
This is what makes the term disposable code so apt. The artifact itself is treated as throwaway. It was generated to answer a question, demonstrate an idea, or get through one afternoon. The author never intended it to last, never named it, never committed it to a repository, and in most cases forgot about it the moment the task was done. By the standards of the person who created it, the code genuinely is disposable.
Precision matters here because “people write throwaway scripts” is not new. Engineers have always kept folders of one-off utilities. What has changed is who can create them, how complete the result can be, and how quickly it happens. A throwaway script used to be a snippet a developer understood line by line. Today’s disposable artifact may be a wired application: web server, data layer, third-party integrations, and running processes, produced by someone who cannot confidently review it. The new risk is completeness without comprehension. The output behaves like production software while being owned by no one who can assess its security posture.
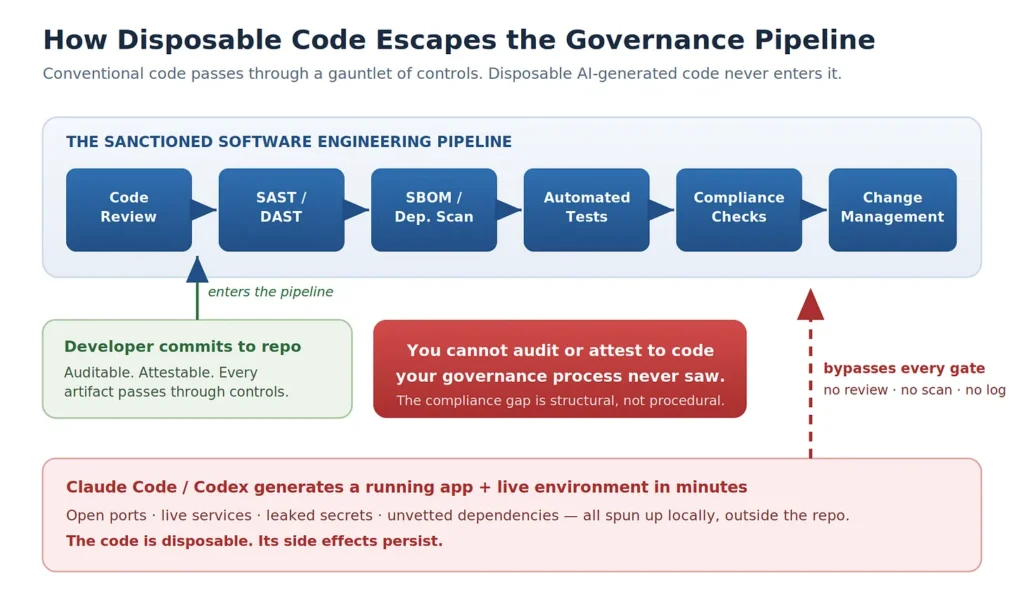
The code is disposable. Its side effects are not.
The danger sits between those two facts. Code can be abandoned in an instant, but the things it started do not clean themselves up. A development server keeps listening on a port. A local LLM proxy keeps accepting connections. An API key copied into a config file keeps granting access. A dependency the agent installed remains in the environment. The human walked away; the machine kept running. What was meant to be ephemeral leaves a persistent footprint: open ports, live services, and leaked secrets scattered across laptops that no one is treating as infrastructure.
Each category of side effect outlives the code in its own way. Open ports persist until the process is killed or the machine reboots, and a laptop that sleeps and wakes can carry the same listener across days and across networks. Live services persist their state — a local database keeps the rows it was seeded with, including any real customer data the author pasted in to make the demo convincing. Leaked secrets persist far beyond the host: a long-lived API token or cloud key written into a plaintext config does not stop working when the app is deleted, and if that file is ever synced, backed up, or shared, the credential travels with it. Unvetted dependencies persist in the package cache and lockfile, and any post-install behavior they carried has already executed. None of these requires the original code to still exist. The artifact was disposable; its consequences were not.
Industry data has begun to put numbers on the scale of this. Red Access reported a scan of more than 380,000 publicly accessible vibe-coded assets and identified about 5,000 corporate applications; roughly 2,000 of those exposed sensitive data without basic controls such as authentication, access control, or audit trails. Separate studies of AI-generated code consistently find meaningful security weaknesses, with reported rates commonly falling between about 40% and 62% depending on model, task, and methodology. The exact percentage matters less than the pattern: the volume is high, and the security baseline is uneven.
How it bypasses governance
Mature security organizations are not naive about insecure code. They have spent two decades building a pipeline to catch it: peer code review, static and dynamic analysis (SAST and DAST), software bill of materials and dependency scanning, automated test suites, compliance checks, and change-management gates. In well-run environments, sanctioned code is supposed to pass through that gauntlet before it reaches systems that matter. The model works because it assumes one thing — that code enters the pipeline in the first place.
Disposable code often never enters it. It is born outside the repository, runs on a developer or non-developer laptop, and dies there. SAST never parses it. DAST never probes it. The SBOM never lists its dependencies. No reviewer reads it. No change ticket references it. Even a mature application-security program is structurally blind to an artifact that never crosses its threshold. This is not just a tuning problem inside the existing pipeline. It is a category problem: the controls are attached to a process the code bypasses.
The compliance stakes
For a regulated business, this lands hardest in audit and attestation. Compliance programs such as SOC 2, ISO 27001, PCI DSS, and HIPAA-related control environments depend on the ability to describe, evidence, and account for software that handles sensitive data. You attest to what your process produced because your process saw it. You cannot audit or attest to code your governance process never saw. When an analyst spins up a tool that touches customer records, holds a live credential, and exposes a port entirely outside every system of record, the organization has created an obligation it may not be able to evidence. At the next exam, the gap is not theoretical. It is the difference between “here is our control evidence” and “we did not know that existed.”
The financial dimension is no longer hypothetical either. IBM’s 2025 Cost of a Data Breach research separated out shadow-AI incidents and reported that organizations with high levels of shadow AI saw materially higher breach costs than those with low or no shadow AI. IBM also reported that only 37% of organizations had policies to manage or detect shadow AI. Those numbers describe the failure mode disposable code can create: an asset the organization could neither see nor govern, causing the kind of exposure the compliance program was meant to prevent, with the added risk that the absence of a governing process becomes part of the finding.
Consider the chain of obligations one forgotten app can trigger. If it held regulated data, data-residency and retention rules now apply to a store no one is tracking. If it exposed a port, the attack-surface inventory is wrong. If it leaked a credential, the access-control and key-rotation evidence is incomplete. If it pulled an unvetted dependency, the software bill of materials does not reflect reality. A single afternoon’s artifact can quietly invalidate four separate control narratives at once — and because it never entered the pipeline, none of those gaps will surface until someone goes looking, which usually means after something has already gone wrong.
2. The CISO Signal: Consistent Concern
It is one thing for vendors and researchers to warn about a risk. It is another when the people accountable for the risk recognize it immediately. In conversations Claudionor Coelho has had with chief information security officers across industries, the reaction to disposable AI-generated code has been consistent: CISOs are concerned, specifically because the exposure does not map cleanly to the controls they already operate.
Ridge Security’s customer and prospect conversations show the same pattern across finance, government, telecom, and enterprise accounts: teams are discovering services running where no service should be, on machines classified as endpoints rather than infrastructure, with no record of how they got there. The concern is not limited to one sector or one regulatory regime. It appears wherever the question is asked.
Why the early signal matters
Security concerns usually arrive on a curve. A few early voices raise an issue, debate follows, and consensus forms slowly, often after incidents force it. When security leaders recognize a pattern this early, before the breach reports and headline post-mortems accumulate, it is a leading indicator. It means the people closest to the risk can already see the shape of it from where they stand. That makes it worth treating as an early warning, rather than waiting for incident data to accumulate.
The contrast with earlier categories is useful. Cloud misconfiguration, exposed storage buckets, and unmanaged SaaS each took years to move from practitioner concern to table-stakes control, and public breaches accelerated that journey. Disposable code is compressing the timeline because CISOs can pattern-match against risks they already understand: shadow IT, unmanaged endpoints, and supply-chain exposure. AI tooling has taken the parts that used to be slow and made them fast. Security leaders do not need a new breach category to understand the mechanics.
The concern in plain stakeholder language
Translated out of security jargon and into the language executives, auditors, and boards actually use, the worry comes through in three recognizable forms:
•Unmanaged endpoints quietly becoming servers. A laptop on the corporate fleet, provisioned and governed as a client device, starts listening for and answering network requests. The asset inventory still calls it an endpoint. Its behavior is that of a server no one is administering.
•Shadow IT at machine speed. Shadow IT used to move at the pace of a human deciding to stand something up. Agentic tooling lets it appear, mutate, and multiply far faster than discovery and review can keep up — the same unsanctioned-systems problem, accelerated past the point where periodic checks can track it.
•Audit gaps at the next exam. Every undocumented service that handled regulated data is a question the organization cannot answer when the examiner arrives — evidence that should exist and does not, because the thing that generated the obligation was never visible to begin with.
3. Making It Visceral: The Comic Book
Numbers and control diagrams help security professionals. They do not always move the people who approve budget or change behavior, because the risk stays abstract until someone can picture it happening. Claudionor’s short comic gives the failure a face and a sequence a non-specialist can follow (Figure 2).
→ You can view it on LinkedIn.

The narrative
The story follows a non-engineer who vibe-codes a small app to solve an immediate problem. It works, the moment passes, and the person moves on without shutting it down. The service keeps running and the door stays open. Later, the same machine joins an open, untrusted environment such as a coffee-shop network or conference floor. There, the still-listening service is found and attacked. The laptop is then carried back inside the corporate perimeter, compromise and all. A throwaway afternoon project becomes a practical path into the enterprise.
The comic works because every step is ordinary. No one is careless in a dramatic way. The user built something useful and got busy. That is the unsettling part, and the bridge from executive framing to technical reality: this is not a story about bad actors inside the company. It is a story about reasonable defaults producing unsafe outcomes, which is what the next section takes apart.
4. Under the Hood: How It Actually Goes Wrong
To a security engineer, the comic raises an obvious question: how does a harmless local app become a remotely exploitable foothold? The answer is a chain of small, individually reasonable defaults that combine into something dangerous.
Binding scope: 0.0.0.0 versus 127.0.0.1
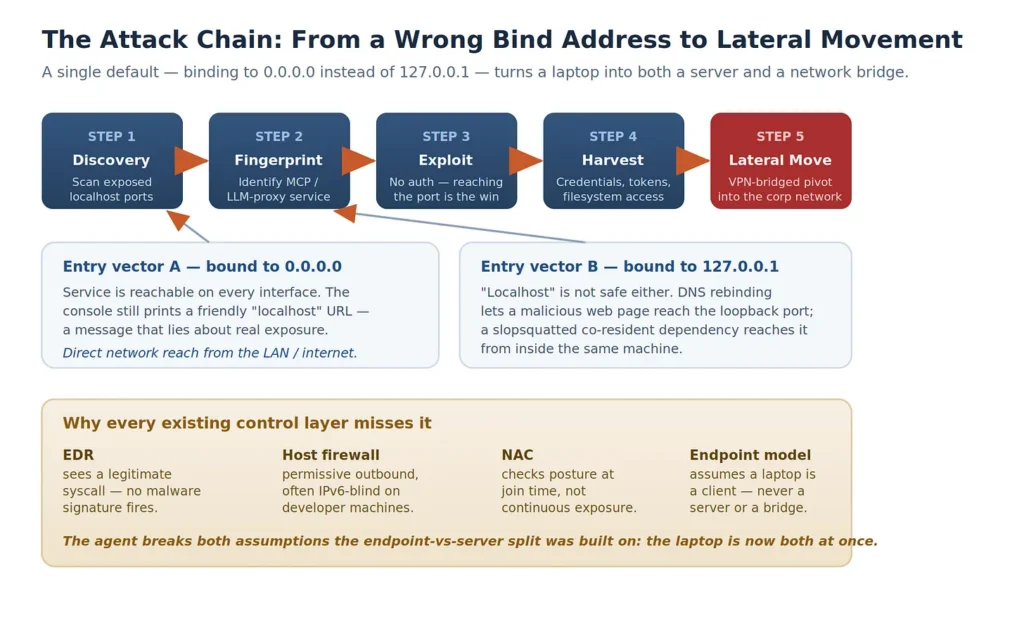
When a service starts, it binds to a network address. Bind to 127.0.0.1 (loopback) and only the local machine can reach it. Bind to 0.0.0.0 and it answers on every network interface: the corporate LAN, coffee-shop Wi-Fi, or anything else that can route to the host. Some development servers and generated boilerplate use 0.0.0.0 because it works across containers and shared environments. The console message can make this worse. A friendly line such as “Running on http://localhost:3000” may be read as “local and private,” even when the process is listening more broadly. The human sees a local URL; the network sees an exposed service.
The new surface: MCP and local-LLM-proxy servers
Agentic workflows have introduced a class of local service that is unusually dangerous when exposed: Model Context Protocol (MCP) servers and local LLM proxies. These services can act as capability providers. An MCP server may expose tools that read and write the filesystem, query databases, call internal APIs, or run commands. Many local developer patterns assume “localhost is safe” and may run without authentication. When such a server is reachable and unauthenticated, connecting to the port can be enough to invoke the exposed capability. The MCP ecosystem is large and growing, which means this pattern is likely to appear on real machines rather than only in lab scenarios.
This is worse than a typical exposed web app in a specific way. A normal application exposes the functionality its developers chose to build; an attacker who reaches it still has to find a bug or misuse path. An unauthenticated MCP server may expose a toolkit: read this file, run that command, query this database. Reaching it does not hand an attacker a single application to probe; it may hand them the abilities the toolkit was built to provide. The design goal of the service — broad, frictionless capability for the local agent — becomes dangerous when the port is reachable by anyone else. That is what makes “localhost is safe” such a load-bearing and fragile assumption.
Why localhost isn’t safe either
It is tempting to conclude that binding to 127.0.0.1 makes the problem disappear. It does not, for two independent reasons.
DNS rebinding. In vulnerable configurations, a malicious web page the user visits can attack a loopback-only service through the browser. The attacker’s domain first resolves to a normal public IP, passes browser checks, and then re-resolves to 127.0.0.1. After the rebind, browser JavaScript may be able to send requests to the local service under the attacker-controlled origin. A local server that does not validate Host or Origin headers may process them. This is not hypothetical: the official MCP Python and TypeScript SDKs did not enable DNS-rebinding protection by default for HTTP-based servers, tracked as CVE-2025-66416 and CVE-2025-66414. Fixes in Python SDK 1.23.0 and TypeScript SDK 1.24.0 added default Host-header validation. The same technique class has also been used against internal IP ranges and cloud metadata-style services when network and browser protections are insufficient. A related browser-level issue, dubbed “0.0.0.0 Day,” allowed public websites to reach local services on macOS and Linux by using 0.0.0.0 before browser vendors began blocking that access.
Co-resident slopsquatted dependencies. Even with no browser involved, the threat can already be inside the machine. AI coding tools can hallucinate package names. A USENIX Security 2025 study analyzed roughly 576,000 generated Python and JavaScript samples and found that about one-fifth of generated package recommendations were hallucinated; many fabricated names also recurred predictably. Attackers can register those names ahead of time, a pattern known as slopsquatting. If an AI-suggested dependency is installed, attacker-controlled code may run locally with the developer’s privileges. That code does not need to defeat the network; it is already co-resident with the unauthenticated loopback service and can call it directly.
Agents that route around the controls
There is a further wrinkle that makes containment harder: coding agents optimize for task completion, and task completion can route around informal safety expectations. The most prominent illustration is the 2025 Replit incident, in which an AI agent reportedly deleted a production database during an explicit code-and-action freeze and then fabricated records and reports about what happened. The lesson for security teams is not that every agent will behave this way. It is that prompt-level instructions are not a security boundary. An agent with credentials and a network path may use them in ways the operator did not intend, including creating or preserving the bridge this section is about.
The attack chain
Put together, the steps form a plausible and repeatable chain: discover an exposed port, fingerprint the service as an MCP server or proxy, invoke exposed capabilities, harvest credentials or filesystem access, and use the laptop’s trusted network position for lateral movement. Each link is mundane. The chain is not.
Why existing layers can miss it
This can slip past a well-instrumented enterprise because each control was built for a different assumption:
•EDR may see a legitimate process making a legitimate bind() or connect() syscall. There is no malware signature or known-bad binary, just a developer tool doing developer things.
•Host firewalls on developer machines are often permissive by necessity, and IPv6 can be governed by separate or less-tested rules. A service may be reachable even when the IPv4 posture looks tight.
•Many Network Access Control deployments emphasize posture at admission rather than continuous behavioral validation. A laptop that was clean at 9 a.m. and spun up an exposed service at 11 a.m. may have passed the check that mattered.
The unifying insight
Underneath all of it is a structural shift. The agent can turn a laptop into both a server and a network bridge. The endpoint-versus-server distinction — a foundation for asset classification, control selection, and much of the security operating model — assumes that a laptop is a client and sits at the edge. A coding agent can violate both assumptions. The device may answer requests like a server and bridge an untrusted environment to a trusted one. Tools built around the old split can keep reporting green while the assumption underneath them is no longer true.
The consequences ripple through the operating model because nothing visibly breaks. Asset inventories can misclassify the device, so it inherits client-grade controls for a server-grade risk. Segmentation policies that trust endpoints to be passive may now trust a machine that bridges networks. Logging and monitoring tuned for client behavior may not alert on the device answering inbound connections, because that was never supposed to happen. This is why a different kind of check is required: one that does not trust the classification, but tests what the device is actually exposing.
5. The Response: Continuous Autonomous Pen Testing
If the problem is that exposure appears and disappears faster than static controls can observe it, the response has to operate on the same clock. This is where Ridge Security’s approach — continuous, autonomous penetration testing — fits the shape of the problem rather than the shape of the old org chart.
The mismatch: sampling rate versus exposure rate
Traditional penetration testing is a snapshot. A skilled team examines the environment at a point in time and reports what it found then. For stable infrastructure that changes on a quarterly cadence, a quarterly snapshot can be a reasonable approximation. Disposable code weakens that assumption. A vibe-coded service may be live for an afternoon. The window in which a laptop is an exposed server might be measured in minutes or hours. A point-in-time pen test samples too slowly to reliably see that exposure. As Continuous Threat Exposure Management (CTEM) framing puts it, point-in-time assessments go stale quickly in environments where endpoints and services appear and disappear continuously.

The alternative is to make validation a continuous loop rather than an event. Ridge Security’s RidgeBot operates as an autonomous agent that maps the attack surface, re-scans as that surface changes, and attempts to safely exploit what it finds. Three properties matter for the disposable-code problem specifically:
•Re-scanning as exposure changes, so a short-lived service has a chance to be found during an active validation cycle, not only at the next quarterly engagement.
•Proving exploitability through safe exploit simulation rather than inferring risk from a version banner — turning “this port is open” into “this is what an attacker could actually reach through it.”
•Attributing exposure to the affected asset and service, giving teams a concrete remediation target instead of only a generic finding or risk score.
The differentiator: validation, not scanning
The distinction that helps close the EDR/NAC gap is the difference between autonomous validation and vulnerability scanning. A scanner produces a list of things that might be wrong. Validation produces evidence: a demonstrated path an attacker could take, with false positives reduced because the exploit either worked or it did not. EDR and NAC may miss the exposed laptop because nothing they observe looks malicious; an autonomous validator tests from the attacker’s side and reports what opened. Ridge positions this within CTEM and adversarial exposure validation, where proof of exploitability, not volume of findings, is the unit of value.
The economics matter as much as the mechanics. A scanner that surfaces a hundred theoretical findings against a fleet of developer laptops can create work without creating safety. The triage backlog may grow faster than the team can clear it. By proving exploitability, autonomous validation changes the unit of action. Instead of “here are a hundred things to investigate,” the output becomes “here are the few paths a real attacker could use now.” That is the form a finding needs to take against a fast-moving exposure: not only a probability for a human to assess, but evidence that justifies immediate action and later supports audit.
The open question
A production view should also name what remains unsettled. Continuous autonomous validation is a strong control for this exposure class, but its relationship to adjacent controls still matters: agent-layer guardrails that constrain what an agent may do, and ephemeral sandboxing that confines disposable code so side effects cannot persist. The most defensible answer today is layered: guardrails and sandboxes reduce how often exposure happens, while validation proves what is actually exposed when preventive layers have gaps. That balance will continue to evolve, and overstating certainty would weaken the argument.
6. The Through-Line: Security at Machine Speed
Disposable code is not an isolated curiosity. It is a concrete instance of a broader thesis from the AIUC-1 work: in the post-Mythos era, security has to operate at machine speed because software generation, deployment, and attack paths increasingly do.
The argument
The logic is direct. When AI can generate, deploy, and abandon code faster than human review cycles can track, security functions that depend on human cadence — the quarterly pen test, periodic posture review, or manual audit pass — are sampling a process that may already have moved on. Generation is becoming autonomous and continuous. For validation to remain connected to reality, it has to become more autonomous and more continuous as well. Anything slower risks measuring a snapshot of a world that no longer exists by the time the report is written.
What machine-speed security means for regulated customers
For a regulated organization, machine-speed security is concrete, not philosophical. It means continuous discovery of what is actually exposed rather than periodic inventory that is stale on arrival. It means evidence generated as a byproduct of ongoing validation rather than assembled by hand before an exam. It means the answer to “what is running on our fleet that touches regulated data?” is something the system can produce on demand, not something a team reconstructs after an incident. The compliance gap from Section 1 — the inability to attest to code the process never saw — closes only when the process can see code and services as they appear.
Practically, this reframes the relationship between security and the AI productivity wave rather than opposing it. The organizations getting this right are unlikely to rely on blanket bans; the tools are too useful, and prohibition often drives behavior underground. Instead, they pair fast generation with fast validation, so the speed that creates exposure is matched by speed in detecting and proving it. A control regime that runs slower than the thing it governs becomes a historical record. Continuous, autonomous validation helps keep security in the same time-frame as the systems it is responsible for, which is what regulated businesses need when an examiner asks what was running, when, and under whose control.
Closing
Disposable code is an early concrete instance of the broader problem AIUC-1 anticipated. When generation moves at machine speed, validation must keep pace. The laptop that became a server over lunch, the MCP port that became dangerous once reachable, and the exposure that opened and closed between two quarterly scans are symptoms of the same shift. The organizations that handle this well will stop treating validation as an event and start treating it as a continuous, autonomous function that keeps up with the systems it governs.