A Web crawler, also referred to as spider or crawler, is a foundation technology in the form of a bot for indexing content on web applications. Examples include web indexing performed by search engines or vulnerability scanning and exploitation by a security testing tool.
Search engine crawlers don’t typically crawl password protected pages, which are naturally considered private information. On the other hand, security testing routinely performs vulnerability scanning of password protected sites as legitimate. Effective vulnerability scanners require a smarter crawling technology that can bypass web logins to examine both public and private pages. In addition to user login credentials, today’s web-based login requirements also include a CAPTCHA.
To meet today’s web security requirements, the RidgeBot 3.3 release is enhanced with a smart crawling technology which can effectively bypass today’s web login requirements without having to install any agents. Once RidgeBot gets access to the protected webpage, it remembers the session information and uses it for further scanning and exploitation. To see how this is done, please schedule a demo with us.
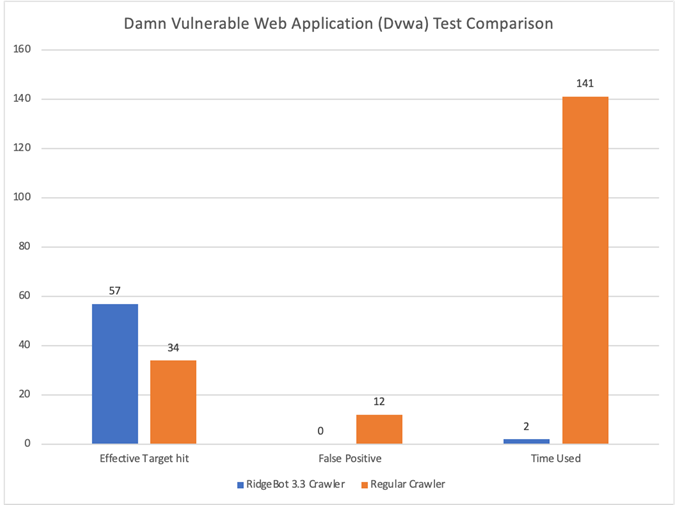
With the RidgeBot Smart Crawling technology, RidgeBot can discover many more attack surfaces and improve the overall efficacy of the vulnerability testing. And the proof is in the pudding: in a benchmark testing done against Damn Vulnerable Web Application (Dvwa), the RidgeBot 3.3 crawler achieved 70% more attack surface discovery, removed false positives and reduced the crawling time from 140 mins to 2min – 70X times faster than a regular crawler (see below chart).